算力直降97%,GPT-3存储只用20MB
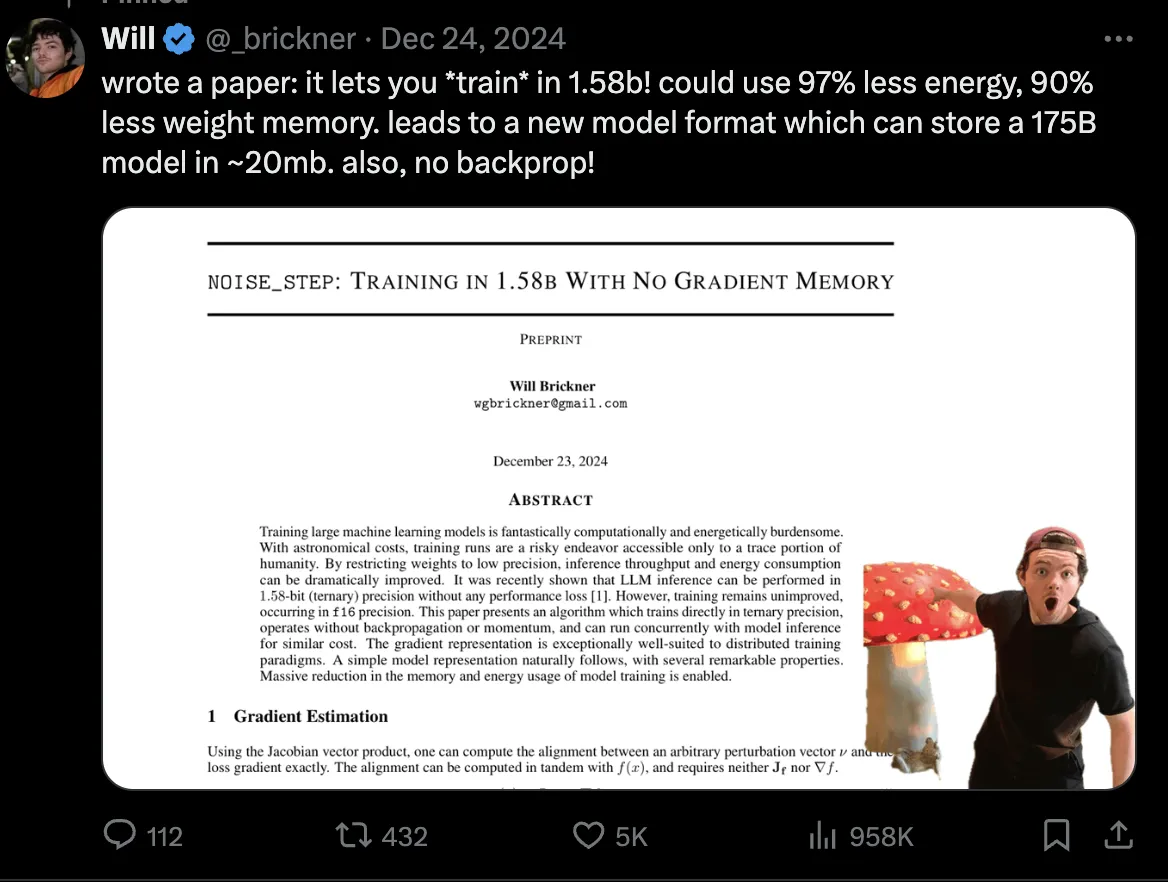
看看浏览量,足见大家对其关注热度。
据其称,他采用了 noise_step 的技术,允许模型在 1.58-bit的低精度下进行训练。
而且无须反向传播或者动量加速。从此减低算力和存储消耗。
我们知道现在的大模型除了训练样本的大(当然还要精),另外的一个大主要体现在对算力的消耗上。
而算力消耗主要也在反向传播的各种存储上。
反向传播作为训练神经网络的核心算法,通过计算损失函数,来进行权重的修正。 每一次反向传播都需要极大量的存储。
如果真的无须反向传播和动量加速,当然可以节省很大的存储。
但是随之而来的局部最优值如何解决。
在 《Gradients without Backpropagation》[1]中,提出了 雅可比向量积(JVP),这种方法可以不依赖反向传播。
在前向传播中引入随机向量,这个随机向量与目标函数的差异可以通过 雅可比向量积来对齐。
通过在多个随机方向上重复JVP计算,可以收集足够的信息来估计整个梯度向量,从而实现不依赖于反向传播的梯度估计。
可灵正式推出虚拟试穿和对口型 API
可灵一直很不错,而且在参加 Coze 大会的时候,周围的人也在夸赞可灵。
大家广泛使用赞美的“虚拟试穿”和“对口型”的对接 API 也开发出来,又是一个让开发者兴奋的点。
价格的话就见仁见智。